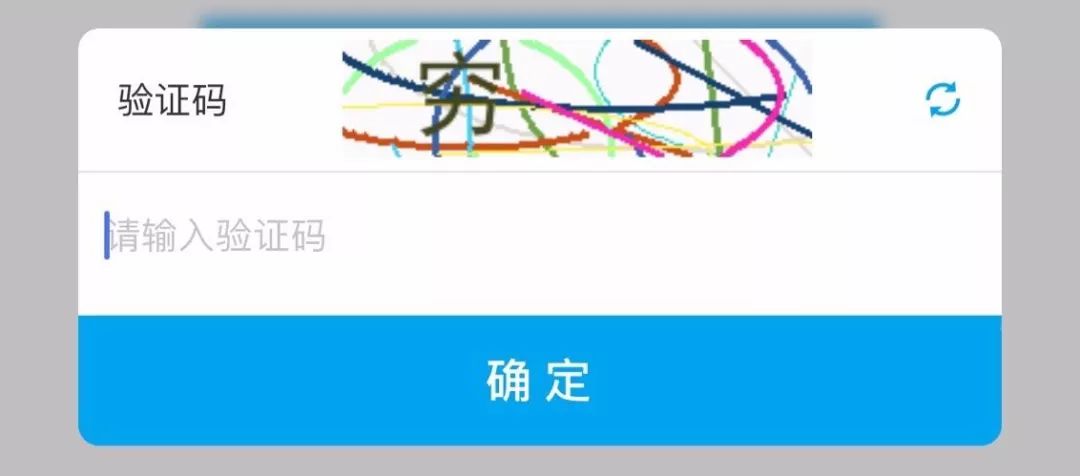
爬虫在处理需要验证码的网站时,识别验证码是一个重要的挑战。验证码通常用于防止自动化脚本的滥用,因此识别验证码通常需要模拟人类的行为和反应。以下是一些常用的识别验证码的方法。
1、光学字符识别(OCR):这是最常见的识别验证码的方法,OCR技术通过图像处理和机器学习算法识别图片中的文字,对于简单的验证码,OCR技术可能足够有效,但对于复杂的验证码,可能需要更高级的技术。
2、深度学习模型:对于复杂的验证码,可以使用深度学习模型进行识别,这些模型可以学习识别图像中的模式,并通过大量的训练数据提高识别准确率,卷积神经网络(CNN)是常用的深度学习模型之一。

3、模板匹配:对于一些固定的验证码图片,可以预先制作模板进行匹配,这种方法需要人工制作模板,适用于验证码样式固定的情况。
4、图形验证码识别服务:有一些第三方服务专门用于识别图形验证码,这些服务使用先进的图像处理和机器学习技术,可以识别大多数常见的验证码,这种方法可能需要成本,并且对于复杂的验证码可能仍然无法100%准确识别。
5、人工干预:如果自动识别的成功率不高,可能需要人工干预,这通常涉及到使用人类来手动解决验证码,然后将结果反馈给爬虫,这种方法成本较高,但可以处理任何类型的验证码。
6、尝试和错误法:对于一些简单的验证码,可以尝试猜测字符,然后根据服务器的反馈来判断是否正确,这种方法效率较低,但对于一些简单的验证码可能有效。
尽管这些方法可以帮助爬虫识别验证码,但许多网站会不断改变他们的验证码策略以防止自动化脚本的滥用,爬虫开发者需要持续适应新的验证码策略并改进他们的方法,请确保在遵守网站的使用政策和服务条款的前提下使用爬虫技术。